[파이썬] Python 자료형(dictionary, list, tuple, set) 총정리
파이썬 딕셔너리 자료형(Dictionary)
파이썬의 딕셔너리는 키=값의 구조로 이루어진 해시 테이블을 의미합니다. 중괄호{}를 사용하여 선언합니다. 값(value)으로 리스트뿐만 아니라 집합 자료형 등도 가능합니다.
a = {'key1':'value1', 'key2':'value2'}
#별도로 추가
a['key3'] = 'value3'
b = {'key1':[1, 2, 3], 'key2': (4, 5, 6)}
c = dict(a='Hello', b='World')
d = {1: 'first', 2: 'second', 3: 'third'}
[실행결과] 키값을 통해 접근 가능합니다.
print (c)
{'a': 'Hello', 'b': 'World'}
print (c['a'])
Hello
비어있는 딕셔너리를 만들고 싶은 경우 dict()함수를 사용합니다.
a = dict()
딕셔너리의 키값과 벨류값만 별도로 보고싶은 경우 .keys()메소드와 .values()메소드를 사용합니다.
items()는 key, value 값를 보여줍니다. 값에 접근하고자하는 겨우 get()메소드를 사용합니다.
c = dict(a='Hello', b='World')
c.keys()
#실행결과
dict_keys(['a', 'b'])
c.items()
#실행결과
dict_items([('a', 'Hello'), ('b', 'World')])
c.values()
#실행결과
dict_values(['Hello', 'World'])
c.get('a')
#실행결과
'Hello'
c.get('c','없음으로 기본값 리턴')
#실행결과
'없음으로 기본값 리턴'
삭제는 리스트와 같은 방법으로 del()함수를 사용합니다.
clear()메소드를 사용하여 딕셔너리의 모든 데이터를 삭제할 수 있습니다.
c = dict(a='Hello', b='World')
del c['a']
print(c)
#실행결과
{'b': 'World'}
c.clear()
print(c)
#실행결과
{}
딕셔너리의 키값의 존재여부를 체크는 방법은 in 키워드를 사용합니다. 결과에 따라 True와 False를 반환합니다.
c = dict(a='Hello', b='World')
del c['a']
print('a' in c)
False
print('b' in c)
True
JSON문자열을 파이썬 딕셔너리(Dictionary)로 변환하기
json.loads()함수를 사용합니다.
import json
jsonstr = '{"a": 1, "b": "Go outside", "name": "홍길동", "insa": "Hello Python"}'
obj = json.loads(jsonstr)
print(type(obj))
print(obj)
print(obj['name'])
#실행결과
<class 'dict'>
{'a': 1, 'b': 'Go outside', 'name': '홍길동', 'insa': 'Hello Python'}
홍길동
다음 샘플코드는 JSON배열을 리스트로 파씽하는 방법입니다. 배열로 접근하게되면 딕셔너리 자료형임을 확인할 수 있습니다.
import json
jsonstr = '[{"name": "홍길동", "insa": "Hello Python"},{"name": "IU", "insa": "Hello IU"}]'
obj = json.loads(jsonstr)
print(type(obj))
print(type(obj[0]))
print(obj[1]['name'])
#실행결과
<class 'list'>
<class 'dict'>
IU
파이썬에서 딕셔너리 자료형을 키 값 기준으로 정렬하는 방법과 리스트를 정렬할 때 sorted()함수를 사용하여 정렬할 수 있습니다.
딕셔너리 key값을 기준으로 정렬하기 (기본 오름차순)
dict_value = {"파이썬": 4, "코딩": 2, "프로그래밍": 1, "Python": 1}
sort_dict = sorted(dict_value.keys())
print(sort_dict)
#실행결과
['Python', '코딩', '파이썬', '프로그래밍']
딕셔너리 key값을 기준으로 내림차순 정렬하기
sorted()함수의 인자값 중 reverse 인자의 값을 True로 적용하면 내림차순이 됩니다. 기본값은 False입니다.
dict_value = {"파이썬": 4, "코딩": 2, "프로그래밍": 1, "Python": 1}
sort_desc_dict = sorted(dict_value.keys(), reverse=True)
print(sort_desc_dict)
#실행결과
['프로그래밍', '파이썬', '코딩', 'Python']
딕셔너리 value값을 기준으로 정렬하기(오름차순)
dict_value = {"파이썬": 4, "코딩": 2, "프로그래밍": 1, "Python": 1}
sort_dict = sorted(dict_value.values())
print(sort_dict)
#실행결과
[1, 1, 2, 4]
딕셔너리 value값을 기준으로 내림차순 정렬하기
dict_value = {"파이썬": 4, "코딩": 2, "프로그래밍": 1, "Python": 1}
sort_dict = sorted(dict_value.values(), reverse=True)
print(sort_dict)
#실행결과
[4, 2, 1, 1]
딕셔너리 와 값 쌍 기준으로 정렬하기
sorted()함수를 사용하여 딕셔너리를 정렬할때 , items()를 사용하는 경우 튜플자료형 타입으로 리턴됩니다.
dict_value = {"파이썬": 4, "코딩": 2, "프로그래밍": 1, "Python": 1}
sort_dict = sorted(dict_value.items()) #튜플자료형으로 리턴됨
print(sort_dict)
#실행결과
[('Python', 1), ('코딩', 2), ('파이썬', 4), ('프로그래밍', 1)]
for key, value in sort_dict:
print(key, ":", value)
#실행결과
Python : 1
코딩 : 2
파이썬 : 4
프로그래밍 : 1
['프로그래밍', '파이썬', '코딩', 'Python']
딕셔너리 키와 값 쌍 기준으로 내림차순 정렬하기
dict_value = {"파이썬": 4, "코딩": 2, "프로그래밍": 1, "Python": 1}
sort_desc_dict = sorted(dict_value.items(), reverse=True)
print(sort_desc_dict)
#실행결과
[('프로그래밍', 1), ('파이썬', 4), ('코딩', 2), ('Python', 1)]
for key, value in sort_desc_dict:
print(key, ":", value)
#실행결과
프로그래밍 : 1
파이썬 : 4
코딩 : 2
Python : 1
람다식(lamda)을 사용하여 정렬하는 방법(오름차순 ASC)
람다식에서 x[0]의 의미는 키(key)값 기준으로 정렬을 의미합니다. x[1]은 값을 기준으로 정렬한다는 것을 의미합니다.
dict_value = {"파이썬": 4, "코딩": 2, "프로그래밍": 1, "Python": 1}
sort_desc_dict = sorted(dict_value.items(), key=lambda x: x[0])
print(sort_desc_dict)
#실행결과
[('Python', 1), ('코딩', 2), ('파이썬', 4), ('프로그래밍', 1)]
dict_value = {"파이썬": 4, "코딩": 2, "프로그래밍": 1, "Python": 1}
sort_desc_dict = sorted(dict_value.items(), key=lambda x: x[1])
print(sort_desc_dict)
#실행결과
[('프로그래밍', 1), ('Python', 1), ('코딩', 2), ('파이썬', 4)]
람다식(lamda)을 사용하여 내림차순 정렬하는 방법(DESC)
dict_value = {"파이썬": 4, "코딩": 2, "프로그래밍": 1, "Python": 1}
sort_desc_dict = sorted(dict_value.items(), key=lambda x: x[0], reverse=True)
print(sort_desc_dict)
#실행결과
[('프로그래밍', 1), ('파이썬', 4), ('코딩', 2), ('Python', 1)]
파이썬 집합자료형 (Set)
중복을 허용하지 않으며, 순서가 없습니다. 순서가 없다는 것은 값을 지정할때 랜덤으로 지정된다는 뜻입니다. 아래 샘플코드의 실행결과를 보면 이해가 빠릅니다.
a = set('Hello World!')
print(a)
[실행결과]
{'d', 'r', 'e', '!', 'H', ' ', 'W', 'l', 'o'}
List와 Tuple은 순서가 있음으로 인덱스 값을 통해 접근할 수 있습니다. Set은 Dictionary와 비슷하게 순서가 없는 자료형임으로 인덱싱을 지원하지않습니다. 이 말은 a[3]과 같은 방법으로 접근하면 TypeError를 발생시킵니다.
>>> print(a[0]) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'set' object is not subscriptable >>>
Set은 교집합, 차집합, 합집합 등 집합 연산에 있어 매우 유리합니다.
a = set([1, 2, 3, 4, 5, 6])
b = set([5, 6, 7, 8, 9, 0])
print(a & b) #실행결과 {5, 6}
print(a | b) #실행결과 {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
print(a - b) #실행결과 {1, 2, 3, 4}
print(b - a) #실행결과 {0, 8, 9, 7}
교집합, 합집합, 차집합의 방법으로 intersection(), union(), difference()메소드를 사용할 수 있습니다.
a = set([1, 2, 3, 4, 5, 6])
b = set([5, 6, 7, 8, 9, 0])
print(a.intersection(b)) #실행결과 {5, 6}
print(a.union(b)) #실행결과 {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
print(a.difference(b)) #실행결과 {1, 2, 3, 4}
print(b.difference(a)) #실행결과 {0, 8, 9, 7}
Set자료형은 add()메소드를 사용하여 값을 추가합니다. 이미 존재하는 값을 추가하는 경우 추가되지 않습니다.
a = set([1, 2, 3, 4, 5, 6])
a.add(22)
print(a)
#실행결과
{1, 2, 3, 4, 5, 6, 22}
a.add(22)
print(a)
{1, 2, 3, 4, 5, 6, 22}
Set자료형은 update()메소드를 사용하여 여러 개의 값을 추가할 수 있습니다. 그 값으로 List나 Tuple과 같은 자료형의 데이터만 추가할 수 있습니다.
a = set([1, 2, 3, 4, 5, 6])
a.update([11])
a.update([11,22,33,44])
print(a)
#실행결과
{1, 2, 3, 4, 5, 6, 33, 11, 44, 22}
Set자료형은 remove()메소드를 사용하여 삭제합니다. 제거 대상의 인덱스가 아닌 값을 지정합니다. 지우려는 값이 없을 경우 KeyError가 발생합니다. 값이 있는 경우에만 삭제됩니다.
a = set([1, 2, 3, 4, 5, 6])
a.remove(1)
print(a)
#실행결과
{2, 3, 4, 5, 6}
set자료형은 discard()메서드를 사용하여 삭제할 수 도 있었어요. remove()와 달리 값이 없어도 오류가 발생하지 않고, 값이 있는 경우에만 삭제합니다. 특정 요소를 안전하게 제거할 수 있는 거죠.
a = set([1, 2, 3, 4, 5, 6]) a.discard(1) print(a) a.discard(1)
set자료형은 pop()메서드를 사용하여 삭제할 수 있습니다. 제일 앞쪽 값부터 삭제합니다.
비어있는 경우 pop()를 시도하면 KeryError: pop form an empty set오류가 발생해요.
a = set([1, 2, 3, 4, 5])
a.pop()
print(a)
a.pop()
print(a)
a.pop()
print(a)
a.pop()
print(a)
a.pop()
print(a)
a.pop()
print(a)
#실행결과
{2, 3, 4, 5}
{3, 4, 5}
{4, 5}
{5}
set()
for문에서 set의 크기에 변화를 주면 RuntimeError: Set changed size during iteration 오류가 발생해요. pop(), add(),discard(),remove() 등의 작업은 오류가 발생하네요. 반복문을 사용할 수 없는 걸까요?
a = set([1, 2, 3, 4, 5])
print(f'초기 사이즈 : {len(a)}')
for i in a:
if len(a) > 0:
a.pop()
#a.add(12)
#a.discard(1)
#a.remove(2)
print(a)
#실행결과
Traceback (most recent call last):
File "C:\python\Workspace\main.py", line 3, in <module>
for i in a:
RuntimeError: Set changed size during iteration
초기 사이즈 : 5
{1, 3, 4, 5}
파이썬 리스트 타입의 자료형(List)
파이썬에서 리스트는 배열이라고 생각하면 됩니다.
a = [] b = [1,2,3,4,5] c = ['Hello','World'] d = [1,2,3, ['Hello', 'World']]
[실행결과]
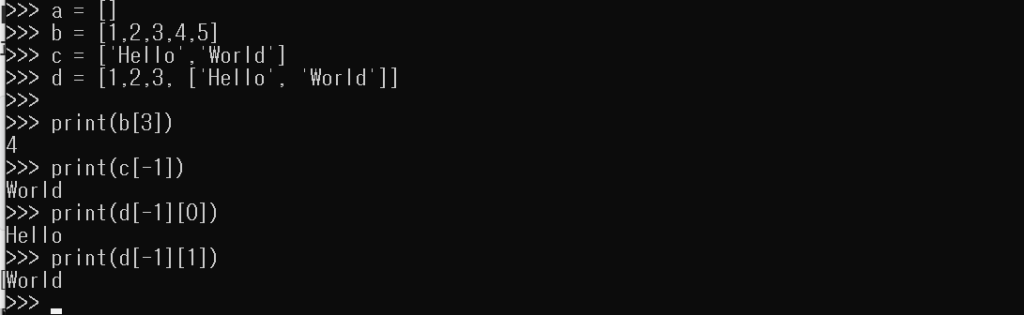
리스트의 값을 변경하는 방법은 인덱스를 지정하여 변경할 수 있습니다.
a = [1,2,3,4,5] a[0] = 'aa' print(a)
[실행결과]
['aa', 2, 3, 4, 5]
리스트의 일부값을 삭제하는 방법 : [ ]처리
a = [1,2,3,4,5] a[3:4] =[] print(a)
[실행결과]
[1, 2, 3, 5]
리스트의 값을 여러개 변경하는 방법
a = [1,2,3,4,5] a[2:3] = ['a','b','c'] print(a)
[실행결과]
[1, 2, 'a', 'b', 'c', 4, 5]
리스트의 일부값을 삭제 하는 방법2 : del 키워드 사용
a = [1,2,3,4,5] del a[1] print(a)
[실행결과]
[1, 3, 4, 5]
파이썬 리스트 함수
| 함수 | 설명 |
| append(추가할 값) | 리스트에 값 추가 |
| extend(확장할 리스트) | 리스트에 리스트를 추가 |
| index(찾을 값) | 리스트에서 찾을 값의 위치를 반환 |
| insert(추가할 위치, 추가할 값) | 리스트에 넣을 위치에 넣을 값을 넣어준다. |
| remove(삭제할 대상 값) | 리스트에서 삭제할 값을 찾아서 삭제 (가장 먼저 나온 값), 인덱스 번호 아님 |
| count(찾을 값) | 리스트에 찾을 값이 몇 개있는지 개수를 세서 반환 |
| sort() | 리스트 정렬 ( 가나다 순으로 정렬 ) |
a = [1,2,3,4,5] a.append(10) a.append(6) a.append(9) print(a)
[실행결과]
[1, 2, 3, 4, 5, 10, 6, 9]
정렬시 리버스(reverse)로 정렬할 경우 reverse = True를 설정한다. 반드시 대문자 T로 시작하는 True로 설정해야한다.
#정렬하기 a.sort() print (a) #리버스 정렬 a.sort(reverse = True) print (a)
[실행결과]
[1, 2, 3, 4, 5, 6, 9, 10] [10, 9, 6, 5, 4, 3, 2, 1]
여러개의 리스트를 하나로 합치는 방법 : + 기호를 사용하여 간단하게 해결됩니다.
b = [1, 2, 3, 4, 5] c = ['Hello', 'World'] a = b + c print(a)
[실행결과]
[1, 2, 3, 4, 5, 'Hello', 'World']
파이썬 리스트 값 중복 제거 하는 방법
set()함수를 사용하면 중복된 값이 제거 됩니다. 그러나 자료형이 set 자료형으로 변경됩니다. 그럼으로 중복 제거 후 리스트 자료형으로 형변환이 필요합니다.
b = [1, 2, 3, 4, 5, 1, 2, 3] c = ['Hello', 'World', 1, 2, 3] a = b + c print(a) #중복제거 d = set(a) #set 자료형 print(type(d)) print(d) #다시 리스트 자료형으로 형변환 e = list(d) print(type(e)) print(e)
[실행결과]
[1, 2, 3, 4, 5, 1, 2, 3, 'Hello', 'World', 1, 2, 3]
<class 'set'>
{1, 2, 3, 4, 5, 'Hello', 'World'}
<class 'list'>
[1, 2, 3, 4, 5, 'Hello', 'World']
파이썬 리스트를 문자열로 변환하는 방법 (list to string)
리스트를 문자열로 변경하는 방법은 join()함수를 사용하여 처리할 수 있다. 주의해야할 점은 하나 있습니다. 리스트의 요소가 가 문자열이 아닌 정수일경우 join문에 바로 적용하면 TypeError: sequence item 0: expected str instance, int foud 오류가 발생됩니다. join문 안에 for문을 사용하여 str()함수를 사용하여 형변환 처리를 해야합니다. 문자열로 변환시 구분자를 추가할 수도 있습니다.
a = [1, 2, 3, 4, 5] str1 = ''.join(a) #실행결과 TypeError: sequence item 0: expected str instance, int found str2 = ''.join(str(e) for e in a) print(str2) #실행결과 12345 b = ['Hello', 'World', 'Python'] str3 = ''.join(a) print(str3) #실행결과 HelloWorldPython b = ['Hello', 'World', 'Python'] #문자열 구분자로 공백을 준 경우 str3 = ' '.join(b) print(str3) #실행결과 Hello World Python #문자열 구분자로 콤마를 준 경우 str3 = ','.join(a) print(str3) #실행결과 Hello,World,Python
파이썬 리스트를 JSON으로 객체로 변환하는 방법(List to JSON)
JSON타입의 문자열이 필요할 경우가 아주 많아요. json모듈을 사용하면 쉽게 변환할 수 있어요. json.dumps()함수를 사용 예제를 살펴봅니니다. 딕셔너리 자료형 역시 JSON으로 동일하게 변환하시면 됩니다.
import json
alist = [{'a': 1, 'b': 2}, {'c': 3, 'd': 4}]
print(type(alist))
jsonstr = json.dumps(alist)
print(jsonstr)
#실행결과
<class 'list'>
[{"a": 1, "b": 2}, {"c": 3, "d": 4}]
이렇게 쉽게 JSON문자열로 변경이 가능해요. 그러나 한글을 사용할때는 한글깨짐 현상이 발생합니다. 한글 깨짐 현상을 해결하기 위해서는 dumps()함수를 사용시 인자값으로 ensure_ascii=False를 처리해주어야 한글이 깨짐을 방지할 수 있습니다.
import json
alist = [{'a': 1, 'b': 2}, {'c': '홍길동', 'd': 'Hello Python'}]
jsonstr = json.dumps(alist)
print(jsonstr)
# 실행결과 한글깨짐현상 발생
[{"a": 1, "b": 2}, {"c": "\ud64d\uae38\ub3d9", "d": "Hello Python"}]
jsonstr = json.dumps(alist, ensure_ascii=False)
print(jsonstr)
#실행결과
[{"a": 1, "b": 2}, {"c": "홍길동", "d": "Hello Python"}]
JSON 문자열을 리스트로 변환하는 방법(JSON to List)
json.loads()함수를 사용하여 변환 가능합니다.
import json
jsonstr = '[{"a": 1, "b": "Go outside"}, {"c": "홍길동", "d": "Hello Python"}]'
alist = json.loads(jsonstr)
print(type(alist))
print(alist)
print(alist[0])
print(alist[0]['b'])
#실행결과
<class 'list'>
[{'a': 1, 'b': 'Go outside'}, {'c': '홍길동', 'd': 'Hello Python'}]
{'a': 1, 'b': 'Go outside'}
Go outside
JSON배열을 파이썬 리스트로 변환하는 방법(JSON Arrays to List)
json.loads()함수를 사용하여 변환가능합니다.
리스트 배열의 값을 출력하는 방법에 대해서 예제코드에 포함하였습니다.
import json
jsonstr = '[[{"a": 1, "b": "Go outside"}], [{"c": "홍길동", "d": "Hello Python"}]]'
alist = json.loads(jsonstr)
print(type(alist))
print(alist)
print(alist[0])
print(alist[0][0])
print(alist[0][0]['b'])
#실행결과
<class 'list'>
[[{'a': 1, 'b': 'Go outside'}], [{'c': '홍길동', 'd': 'Hello Python'}]]
[{'a': 1, 'b': 'Go outside'}]
{'a': 1, 'b': 'Go outside'}
Go outside
파이썬 튜플 자료형(Tuple) : Immutable
List와 비슷합니다. 차이점은 READ-ONLY!!! 한번 지정한 값은 변경할 수 없습니다.
List는 [ ]대괄호를 사용하여 묶지만, Tuple은 ( ) 소괄호로 묶어서 사용하며, 소괄호는 생략할 수 있습니다.
또하나의 List와 다른점은 값의 구분자로 콤마(,)를 사용해야합니다.
a = (1, 2, 3, 4, 5) b = (1, 2, (3, 4, 5)) c = () d = 1, 2, 3
